💻 Seminar 1
Hidden Curriculum
26 Sep 2024
Background
Background
Think about the following:
for most of the history of science, and really all the social sciences, there was practically no data – only theories about data
Today we are drowning in data (remember the memes)
Ordinary people have more data than they know what to do with
- Smart watches, sleep data, calories, screen time bla bla bla
As such, in causal inference (or any quantitative work) it’s hard to separate the question from the actual work (programming)
Code and Software
For causal Inference we need:
- Data
- Software for data (Stata for example)
- Understanding of statistics
- Programming skills
Which softare?
- R, Stata, Python, SAS, SPSS
Today we are going to see Language agnostic programming principnes that are usually not covered in econ classes
Making mistakes
Once upon a time there were 2 young researchers that spent 8 months trying to disprove an important work in political psychology (i.e. liberals are less biased than conservatives)
After about 10 conference presentations, half a dozen talks
They decided to send an email to the people they were trying to disprove and send the paper for publication
Making mistakes
The original (super famous) academics came back suggesting that their analysis doesn’t produce the same results
Digging in their directories, the youngsters found countless versions of codes and data - hundreds of files with randome names
And once the code was running again, they found a critical coding error (one comma missing) that corrected (destroyed) their results
The youngsters were devastated. Took them another 2 years to pick up the courage, redo the work and actually disprove the original paper
Anna Karenina Principle
Happy families are all alike; every unhappy family is unhappy in its own way - Leo Tolstoy, Anna Karenina
Good empirical work is all alike; every bad empirical work is bad in its own way - Scott Cunningham, Causal Mixtape
What do we learn?
Most mistakes are not due to insufficient knowledge of coding
The cose of most errors is due to poorly designed empirical workflow
This is why we ll spend a whole seminar on this
Workflow
Workflow
Definition:
A workflow consists of an orchestrated and repeatable pattern of activity, enabled by the systematic organization of resources into processes that transform materials, provide services, or process information
Empirical Workflow
Workflow is like a checklist you bind yourself to when you get your hands on data
- It’s like a morning routine:
- Alarm goes off
- You wash up
- Make coffee
- It’s like a morning routine:
Empirical workflow is a core set of tasks which as you mature you build from experience
- Finding the outlier errors is difficult
- Workflows are to catch the most common errors
- It’s like an intermediate step between getting data and analysing data
Checklist
Empirical workflows are really just a checklist of actions you will take before analyzing ANY data
It is imperative that you don’t start analysing the data until the list is checked off
RESIST IT
It should be a few, simple, yet non-negotiable, programming commands and exercises to check for errors
We ll go over mine - feel free to add your own if you want
Empirical workflows require scarce time inputs
- All of us are living at the edge of our resource constraints, and our most scarce resources is time
- To do anything, we must sacrifice something else because all activities use time
- Data work is like a marathon:
- Involves far more time training than running - involves far more time doing tedious and repetitive tasks
- Since tedious task are repeated, the have the most potential for error
- Especially for dissertations - However long you thing cleaning and organising data will take, multiply by 10
Step 1 - Read the codebook
Datasets often come with very large documetns describing in detail the production of data
You mush become as much of an expert on the codebook as you are on your own research topic
Allows to interpret the data you acquired
Set aside time to study it and keep it handy
Same goes for readme files that go with some datasets
Do Not Touch the Original Data

Do Not Touch the Original Data
Empirical workflows require data manipulation
It is imperative taht you always only work with copies
Never save over the original dataset - be careful of softwares like excel that may do it automatically
Avoid this by storing the raw data separate from copies
If you alter the raw data, you might never have the chance to get them back
Step 2 - Folder Structure and Directories
After our error, I did an extensive research on how problems like these tend to happen
Came back wit hthe following important steps
- Hierarchical folder structure
- Automation
- Naming convention
- Version Control
Step 2 - Helping your future self
Remember your future self is also operating at the edge of her production possibilities
The typical quantitative project may have hundreds of files of various types and will take years from first thought to completion
So imagine if all files are not stored together, without some sort of archivign
Best way to resolve this is hierarchical folder structures
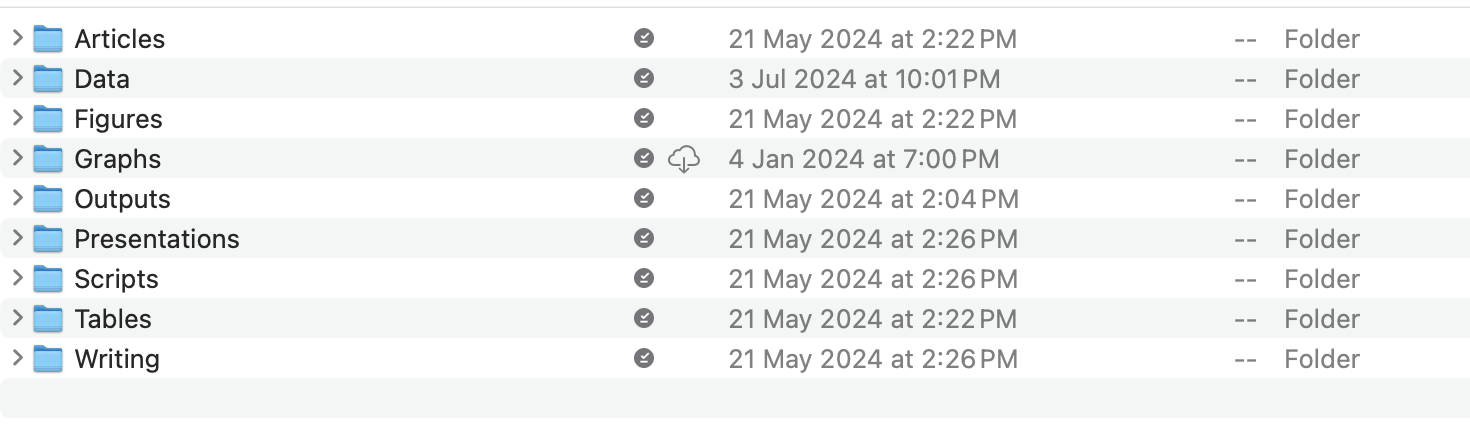
Step 2 - Subdirectory organisation
Step 2 - Automation
- Avoid as much as possible copy pasting information
- Your future self doesn’t remember 4 weeks/months from now how you made these tables and figures
- Use a code notebook (do file in Stata) where all commands you run are kept together in order
- Every final output should be able to be reproduced by just pressing one run command
Step 2 - Beautiful Code
Your ideal goal is to make beautiful code
At minimum, don’t make it ugly - unreadable for your future self
Consider a new text editor like Visual Studio Code which allows for
- Colored syntax
- Indentation
- Column editing and more
Stata and R come with their own editors but Visual Studio allows you to have one for all
Step 3 - Eyeballing
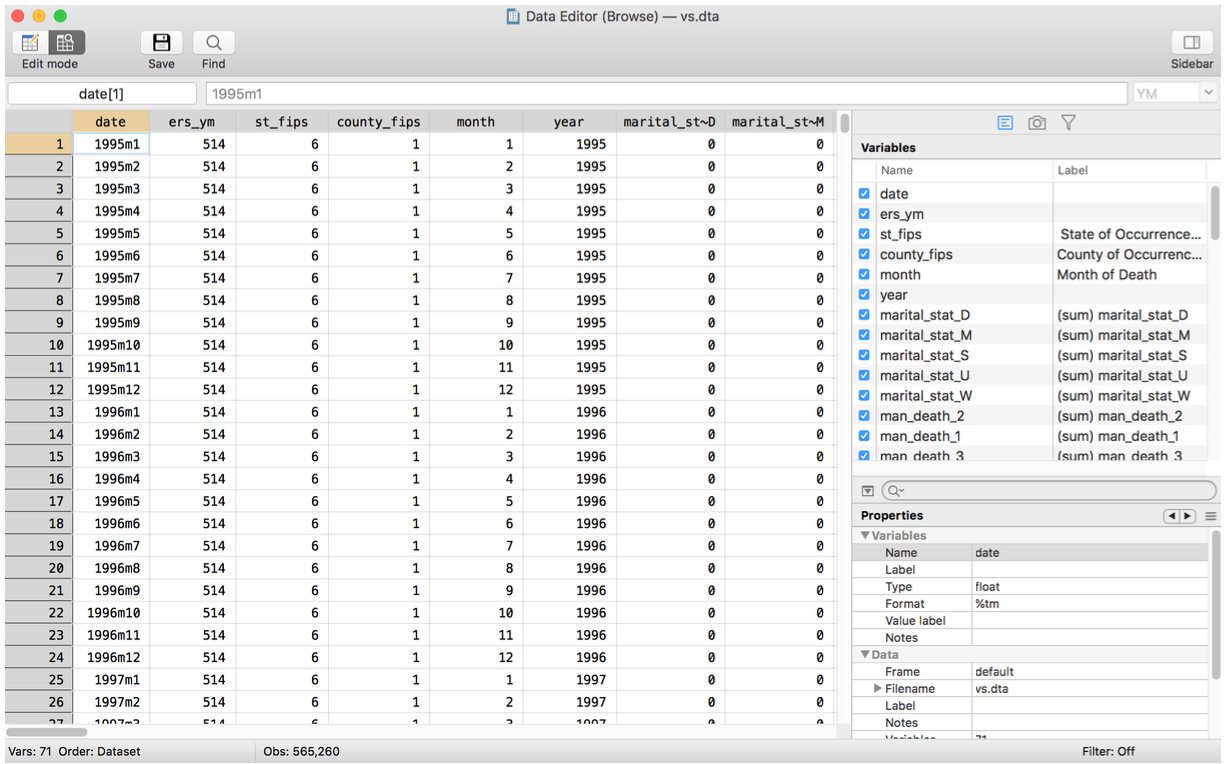
Step 3 - Eyeballing
Human eyes have evolved to spot patterns
We can therefore use it to find things that belong and those that don’t
First just scan the data in its spreadsheet form - get comfortable with what you are going to be using
Browse for Stata for example
Use this to see if anything jumps out
Step 4 - Missing observations
Check the size of your dataset in Stata using count
Check the number of observations per variable in stata using summarize or summ
Use tabulate also to check if, very oftern, missing observations are recorded with a -9 or -1 or 9999 (some illogical - probably- negative value)

PB4A7- Quantitative Applications for Behavioural Science